Apriori 算法
关联规则挖掘是数据挖掘领域的热点,关联规则反映一个对象与其他对象之间的相互依赖关系,如果多个对象之间存在一定的关联关系,那么一个对象可以通过其他对象进行预测。关联规则挖掘一般可分成两个步骤:
-
找出所有支持度大于等于最小支持度阈值的频繁项集。
-
由频繁模式生成满足可信度阈值的关联规则。
最著名的关联规则挖掘的方法是 Apriori 算法,该算法的命名源于算法使用了频繁项集性质的先验(Prior)知识。自从 Rakesh Agrawal 等在 1993 年首次提出顾客交易数据库中项集间关联规则挖掘问题后,很多研究人员对此问题进行了大量研究。1994 年,Rakesh Agrawal 和 Ramakrishnan Srikant 在 Fast algorithms for mining association rules in large databases 一文中正�式提出 Apriori 算法用于挖掘数据库中频繁项集。
以下交易为例
| 交易号码 | 商品 |
|---|---|
| 001 | 豆奶,莴苣 |
| 002 | 莴苣,尿布,啤酒,甜菜 |
| 003 | 豆奶,尿布,啤酒,橙汁 |
| 004 | 莴苣,豆奶,尿布,啤酒 |
| 005 | 莴苣,豆奶,尿布,橙汁 |
关联规则
若 , 均为项集,且 ,,并且 ,用蕴含式 表示一个关联规则。它表示某些项(X 项集)在一个事务中的出现,可推导出另一些项(Y 项集)在同一事务中也出现。
这里,“=>” 称为 “关联” 操作, 称为关联规则的前提, ��称为关联规则的结果。
支持度
支持度表示该数据项在事务中出现的频度。 数据项集 X 的支持度 是 D 中包含 X 的事务数量与 D 的总事务数量之比,如下公式所示。
关联规则 的支持度等于项集 的支持度,如下公式所示。
如果 大于等于用户指定的最小支持度 ,则称 X 为频繁项目集,否则称 X 为非频繁项目集。
置信度
置信度也称为可信度,规则 的置信度表示 D 中包含 X 的事务中有多大可能性也包含 Y。表示的是这个规则确定性的强度,记作 。通常,用户会根据自己的挖掘需要来指定最小置信度阈值,记为 。
如果数据项集 X 满足 ,则 X 是频繁数据项集。若规则 同时满足 ,则称该规则为强关联规则,否则称为弱关联规则。一般由用户给定最小置��信度阈值和最小支持度阈值。发现关联规则的任务就是从数据库中发现那些置信度、支持度大于等于给定最小阈值的强关联规则。
 以下用代码批量计算
以下用代码批量计算
代码
# 1. 导入必要的库import pandas as pdfrom mlxtend.preprocessing import TransactionEncoderfrom mlxtend.frequent_patterns import apriori, association_rules
# 2. 读取数据data = [ ['豆奶', '莴苣'], ['莴苣', '尿布', '啤酒', '甜菜'], ['豆奶', '尿布', '啤酒', '橙汁'], ['莴苣', '豆奶', '尿布', '啤酒'], ['莴苣', '豆奶', '尿布', '橙汁']]
# 3. 数据预处理te = TransactionEncoder()te_ary = te.fit(data).transform(data)df = pd.DataFrame(te_ary, columns=te.columns_)
# 4. 使用Apriori算法找出频繁项集frequent_itemsets = apriori(df, min_support=0.6, use_colnames=True)
# 5. 从频繁项集中生成关联规则rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.7)# 打印关联规则的中文解释for index, rule in rules.iterrows(): print("规则#" + str(index+1)) print("如果购买了: " + ', '.join(list(rule['antecedents']))) print("那么也可能购买: " + ', '.join(list(rule['consequents']))) print("支持度: " + str(rule['support'])) print("置信度: " + str(rule['confidence'])) print("提升度: " + str(rule['lift'])) print("====================================")
pd.set_option('display.max_columns', None) # 显示所有列pd.set_option('display.max_rows', None) # 显示所有行print(rules.head(5))输出
规则#1如果购买了: 尿布那么也可能购买: 啤酒支持度: 0.6置信度: 0.7499999999999999提升度: 1.2499999999999998====================================规则#2如果购买了: 啤酒那么也可能购买: 尿布支持度: 0.6置信度: 1.0提升度: 1.25====================================规则#3如果购买了: 莴苣那么也可能购买: 尿布支持度: 0.6置信度: 0.7499999999999999提升度: 0.9374999999999998====================================规则#4如果购买了: 尿布那么也可能购买: 莴苣支持度: 0.6置信度: 0.7499999999999999提升度: 0.9374999999999998====================================规则#5如果购买了: 尿布那么也可能购买: 豆奶支持度: 0.6置信度: 0.7499999999999999提升度: 0.9374999999999998====================================规则#6如果购买了: 豆奶那么也可能购买: 尿布支持度: 0.6置信度: 0.7499999999999999提升度: 0.9374999999999998====================================规则#7如果购买了: 莴苣那么也可能购买: 豆奶支持度: 0.6置信度: 0.7499999999999999提升度: 0.9374999999999998====================================规则#8如果购买了: 豆奶那么也可能购买: 莴苣支持度: 0.6置信度: 0.7499999999999999提升度: 0.9374999999999998==================================== antecedents consequents antecedent support consequent support support \0 (尿布) (啤酒) 0.8 0.6 0.61 (啤酒) (尿布) 0.6 0.8 0.62 (莴苣) (尿布) 0.8 0.8 0.63 (尿布) (莴苣) 0.8 0.8 0.64 (尿布) (豆奶) 0.8 0.8 0.6
confidence lift leverage conviction zhangs_metric0 0.75 1.2500 0.12 1.6 1.001 1.00 1.2500 0.12 inf 0.502 0.75 0.9375 -0.04 0.8 -0.253 0.75 0.9375 -0.04 0.8 -0.254 0.75 0.9375 -0.04 0.8 -0.25算法描述
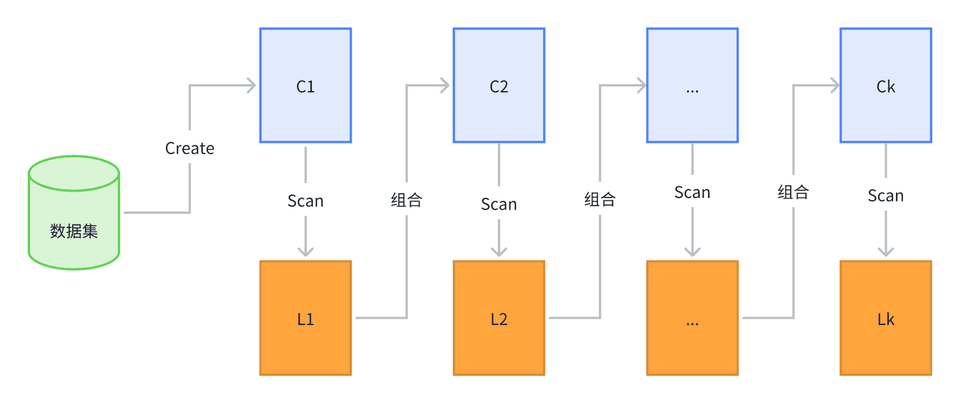
Apriori 算法的核心是基于两阶段频繁项集的递推算法。挖掘出来的关联规则属于单维、单层、布尔关联规则。在具体实现时,Apriori 算法将发现关联规则挖掘过程分解为两个步骤:
-
通过迭代,检索出事务数据库中所有频繁项集。即找出事务数据库 D 中所有大于等于用户指定最小支持度阈值的项目集 (itemset)。
-
利用频繁项目集挖掘出满足用户需要的强关联规则。即找出那些支持度和置信度大于等于用户给定的支持度和置信度阈值的关联规则。
在挖掘关联规则的整个执行过程中第一步,即寻找频繁项集是关联挖掘的核心,也占据了整个计算量的大部分,决定了挖掘关联规则的总体性能。这是因为有 m 个项形成的不同项集的数目可达到 2 ͫ -1 个,尤其在海量数据库中,是一个 NP 难度问题。第二步则相对容易,因为它只需要在第一步找到的频繁项集的基础上列出所有可能的关联规则,同时,找出满足支持度和置信度要求的强关联规则即可。由于频繁项集已经满足了支持度的要求,因此只需要判断置信度是否满足要求就可以得出结果。